Connectivity#
Written by Luke Chang
So far, we have primarily been focusing on analyses related to task evoked brain activity. However, an entirely different way to study the brain is to characterize how it is intrinsically connected. There are many different ways to study functional connectivity.
The primary division is studying how brain regions are structurally connected. In animal studies this might involve directly tracing bundles of neurons that are connected to other neurons. Diffusion imaging is a common way in which we can map how bundles of white matter are connected to each region, based on the direction in which water diffuses along white matter tracks. There are many different techniques such as fractional ansiotropy and probablistic tractography. We will not be discussing structural connectivity in this course.
An alternative approach to studying connectivity is to examine how brain regions covary with each other in time. This is referred to as functional connectivity, but it is better to think about it as temporal covariation between regions as this does not necessarily imply that two regions are directly communication with each other.
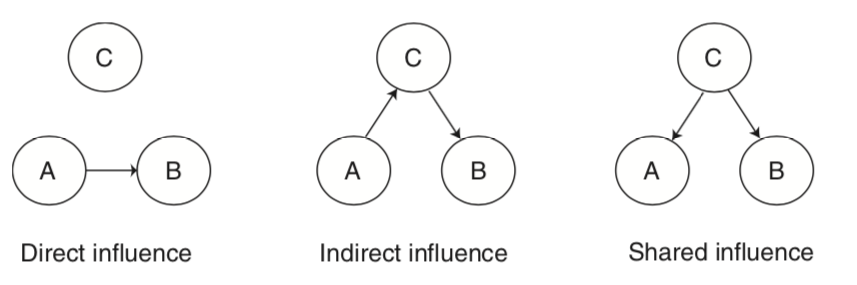
For example, regions can directly influence each other, or they can indirectly influence each other via a mediating region, or they can be affected similarly by a shared influence. These types of figures are often called graphs. These types of graphical models can be directed or undirected. Directed graphs imply a causal relationship, where one region A directly influence another region B. Directed graphs or causal models are typically described as effective connectivity, while undirected graphs in which the relationship is presumed to be bidirectional are what we typically describe as functional connectivity.
In this tutorial, we will work through examples on:
Seed-based functional connectivity
Psychophysiological interactions
Principal Components Analysis
Graph Theory
Let’s start by watching a short overview of connectivity by Martin Lindquist.
from IPython.display import YouTubeVideo
YouTubeVideo('J0KX_rW0hmc')
Now, let’s dive in a little bit deeper into the specific details of functional connectivity.
YouTubeVideo('OVAQujut_1o')
Functional Connectivity#
Seed Voxel Correlations#
One relatively simple way to calculate functional connectivity is to compute the temporal correlation between two regions of interest (ROIs). Typically, this is done by extracting the temporal response from a seed voxel or the average response within a seed region. Then this time course is regressed against all other voxels in the brain to produce a whole brain map of anywhere that shares a similar time course to the seed.
Let’s try it ourselves with an example subject from the Pinel Localizer dataset. First, let’s import the modules we need for this tutorial and set our paths.
%matplotlib inline
import os
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from nltools.data import Brain_Data, Design_Matrix, Adjacency
from nltools.mask import expand_mask, roi_to_brain
from nltools.stats import zscore, fdr, one_sample_permutation
from nltools.file_reader import onsets_to_dm
from nltools.plotting import component_viewer
from scipy.stats import binom, ttest_1samp
from sklearn.metrics import pairwise_distances
from copy import deepcopy
import networkx as nx
from nilearn.plotting import plot_stat_map, view_img_on_surf
from bids import BIDSLayout, BIDSValidator
import nibabel as nib
base_dir = '..'
data_dir = os.path.join(base_dir, 'data', 'localizer')
layout = BIDSLayout(data_dir, derivatives=True)
Now let’s load an example participant’s preprocessed functional data.
sub = 'S01'
fwhm=6
data = Brain_Data(layout.get(subject=sub, task='localizer', scope='derivatives', suffix='bold', extension='nii.gz', return_type='file')[0])
smoothed = data.smooth(fwhm=fwhm)
Next we need to pick an ROI. Pretty much any type of ROI will work.
In this example, we will be using a whole brain parcellation based on similar patterns of coactivation across over 10,000 published studies available in neurosynth (see this paper for more details). We will be using a parcellation of 50 different functionally similar ROIs.
mask = Brain_Data('../masks/k50_2mm.nii.gz')
mask = Brain_Data('https://neurovault.org/media/images/8423/k50_2mm.nii.gz')
mask.plot()

Each ROI in this parcellation has its own unique number. We can expand this so that each ROI becomes its own binary mask using nltools.mask.expand_mask.
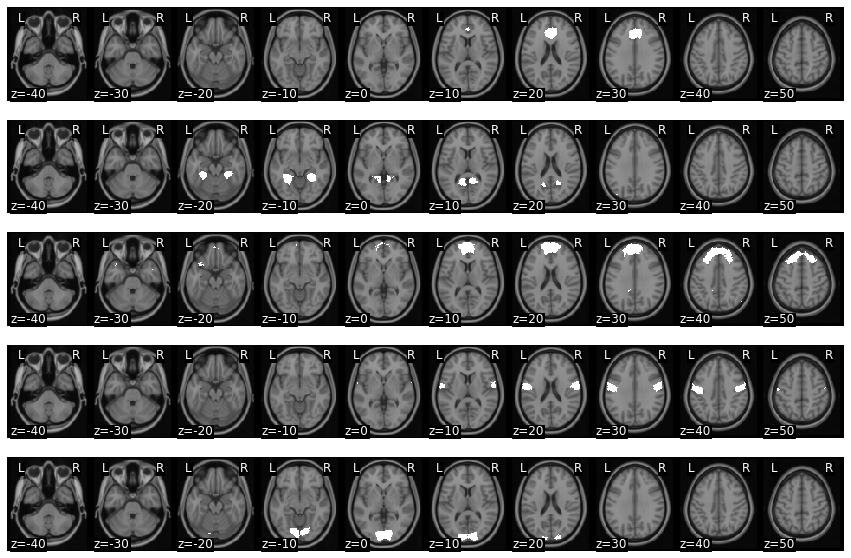
Let’s plot the first 5 masks.
mask_x = expand_mask(mask)
f = mask_x[0:5].plot()
To use any mask we just need to index it by the correct label.
Let’s start by using the vmPFC mask (ROI=32) to use as a seed in a functional connectivity analysis.
vmpfc = smoothed.extract_roi(mask=mask_x[32])
plt.figure(figsize=(15,5))
plt.plot(vmpfc, linewidth=3)
plt.ylabel('Mean Intensitiy', fontsize=18)
plt.xlabel('Time (TRs)', fontsize=18)
Text(0.5, 0, 'Time (TRs)')
Okay, now let’s build our regression design matrix to perform the whole-brain functional connectivity analysis.
The goal is to find which regions in the brain have a similar time course to the vmPFC, controlling for all of our covariates (i.e., nuisance regressors).
Functional connectivity analyses are particularly sensitive to artifacts that might induce a temporal relationship, particularly head motion (See this article by Jonathan Power for more details). This means that we will need to use slightly different steps to preprocess data for this type of analyis then a typical event related mass univariate analysis.
We are going to remove the mean from our vmPFC signal. We are also going to include the average activity in CSF as an additional nuisance regressor to remove physiological artifacts. Finally, we will be including our 24 motion covariates as well as linear and quadratic trends. We need to be a little careful about filtering as the normal high pass filter for an event related design might be too short and will remove potential signals of interest.
Resting state researchers also often remove the global signal, which can reduce physiological and motion related artifacts and also increase the likelihood of observing negative relationships with your seed regressor (i.e., anticorrelated). This procedure has remained quite controversial in practice (see here here, here, and here for a more in depth discussion). We think that in general including covariates like CSF should be sufficient. It is also common to additionally include covariates from white matter masks, and also multiple principal components of this signal rather than just the mean (see more details about compcorr.
Overall, this code should seem very familiar as it is pretty much the same procedure we used in the single subject GLM tutorial. However, instead of modeling the task design, we are interested in calculating the functional connectivity with the vmPFC.
tr = layout.get_tr()
fwhm = 6
n_tr = len(data)
def make_motion_covariates(mc, tr):
z_mc = zscore(mc)
all_mc = pd.concat([z_mc, z_mc**2, z_mc.diff(), z_mc.diff()**2], axis=1)
all_mc.fillna(value=0, inplace=True)
return Design_Matrix(all_mc, sampling_freq=1/tr)
vmpfc = zscore(pd.DataFrame(vmpfc, columns=['vmpfc']))
csf_mask = Brain_Data(os.path.join(base_dir, 'masks', 'csf.nii.gz'))
csf_mask = csf_mask.threshold(upper=0.7, binarize=True)
csf = zscore(pd.DataFrame(smoothed.extract_roi(mask=csf_mask).T, columns=['csf']))
spikes = smoothed.find_spikes(global_spike_cutoff=3, diff_spike_cutoff=3)
covariates = pd.read_csv(layout.get(subject=sub, scope='derivatives', extension='.tsv')[0].path, sep='\t')
mc = covariates[['trans_x','trans_y','trans_z','rot_x', 'rot_y', 'rot_z']]
mc_cov = make_motion_covariates(mc, tr)
dm = Design_Matrix(pd.concat([vmpfc, csf, mc_cov, spikes.drop(labels='TR', axis=1)], axis=1), sampling_freq=1/tr)
dm = dm.add_poly(order=2, include_lower=True)
smoothed.X = dm
stats = smoothed.regress()
vmpfc_conn = stats['beta'][0]
vmpfc_conn.threshold(upper=25, lower=-25).plot()

Notice how this analysis identifies the default network? This analysis is very similar to the original papers that identified the default mode network using resting state data.
For an actual analysis, we would need to repeat this procedure over all of the participants in our sample and then perform a second level group analysis to identify which voxels are consistently coactive with the vmPFC. We will explore group level analyses in the exercises.
Psychophysiological Interactions#
Suppose we were interested in seeing if the vmPFC was connected to other regions differently when performing a finger tapping task compared to all other conditions. To compute this analysis, we will need to create a new design matrix that combines the motor regressors and then calculates an interaction term between the seed region activity (e.g., vmpfc) and the condition of interest (e.g., motor).
This type of analysis called, psychophysiological interactions was originally proposed by Friston et al., 1997. For a more hands on and practical discussion read this paper and watch this video by Jeanette Mumford and a follow up video) of a more generalized method.
nib.load(layout.get(subject='S01', scope='raw', suffix='bold')[0].path)
<nibabel.nifti1.Nifti1Image at 0x7facc4387e10>
def load_bids_events(layout, subject):
'''Create a design_matrix instance from BIDS event file'''
tr = layout.get_tr()
n_tr = nib.load(layout.get(subject=subject, scope='raw', suffix='bold')[0].path).shape[-1]
onsets = pd.read_csv(layout.get(subject=subject, suffix='events')[0].path, sep='\t')
onsets.columns = ['Onset', 'Duration', 'Stim']
return onsets_to_dm(onsets, sampling_freq=1/tr, run_length=n_tr)
dm = load_bids_events(layout, 'S01')
motor_variables = ['video_left_hand','audio_left_hand', 'video_right_hand', 'audio_right_hand']
ppi_dm = dm.drop(motor_variables, axis=1)
ppi_dm['motor'] = pd.Series(dm.loc[:, motor_variables].sum(axis=1))
ppi_dm_conv = ppi_dm.convolve()
ppi_dm_conv['vmpfc'] = vmpfc
ppi_dm_conv['vmpfc_motor'] = ppi_dm_conv['vmpfc']*ppi_dm_conv['motor_c0']
dm = Design_Matrix(pd.concat([ppi_dm_conv, csf, mc_cov, spikes.drop(labels='TR', axis=1)], axis=1), sampling_freq=1/tr)
dm = dm.add_poly(order=2, include_lower=True)
dm.heatmap()
/Users/lukechang/anaconda3/lib/python3.7/site-packages/nltools-0.4.2-py3.7.egg/nltools/file_reader.py:141: UserWarning: Computed onsets for video_right_hand are inconsistent with expected values. Please manually verify the outputted Design_Matrix!
f"Computed onsets for {data.Stim.unique()[i]} are inconsistent with expected values. Please manually verify the outputted Design_Matrix!"
/Users/lukechang/anaconda3/lib/python3.7/site-packages/nltools-0.4.2-py3.7.egg/nltools/file_reader.py:141: UserWarning: Computed onsets for video_left_hand are inconsistent with expected values. Please manually verify the outputted Design_Matrix!
f"Computed onsets for {data.Stim.unique()[i]} are inconsistent with expected values. Please manually verify the outputted Design_Matrix!"
/Users/lukechang/anaconda3/lib/python3.7/site-packages/nltools-0.4.2-py3.7.egg/nltools/file_reader.py:141: UserWarning: Computed onsets for audio_computation are inconsistent with expected values. Please manually verify the outputted Design_Matrix!
f"Computed onsets for {data.Stim.unique()[i]} are inconsistent with expected values. Please manually verify the outputted Design_Matrix!"

Okay, now we are ready to run the regression analysis and inspect the interaction term to find regions where the connectivity profile changes as a function of the motor task.
We will run the regression and smooth all of the images, and then examine the beta image for the PPI interaction term.
smoothed.X = dm
ppi_stats = smoothed.regress()
vmpfc_motor_ppi = ppi_stats['beta'][int(np.where(smoothed.X.columns=='vmpfc_motor')[0][0])]
vmpfc_motor_ppi.plot()

This analysis tells us which regions are more functionally connected with the vmPFC during the motor conditions relative to the rest of experiment.
We can make a thresholded interactive plot to interrogate these results, but it looks like it identifies the ACC/pre-SMA.
vmpfc_motor_ppi.iplot()
Dynamic Connectivity#
All of the methods we have discussed so far assume that the relationship between two regions is stationary - or remains constant over the entire dataset. However, it is possible that voxels are connected to other voxels at specific points in time, but then change how they are connected when they are computing a different function or in different psychological state.
Time-varying connectivity is beyond the scope of the current tutorial, but we encourage you to watch this video from Principles of fMRI for more details
Effective Connectivity#
Effective connectivity refers to the degree that one brain region has a directed influence on another region. This approach requires making a number of assumptions about the data and requires testing how well a particular model describes the data. Typically, most researchers will create a model of a small number of nodes and compare different models to each other. This is because the overall model fit is typically in itself uninterpretable and because formulating large models can be quite difficult and computationally expensive. The number of connections can be calculated as:
\(connections = \frac{n(n-1)}{2}\), where \(n\) is the total number of nodes.
Let’s watch a short video by Martin Lindquist that provides an overview to different approaches to effectivity connectivity.
YouTubeVideo('gv5ENgW0bbs')
Structural Equation Modeling#
Structural equation modeling (SEM) is one early technique that was used to model the causal relationship between multiple nodes. SEM requires specifying a causal relationship between nodes in terms of a set of linear equations. The parameters of this system of equations reflects the connectivity matrix. Users are expected to formulate their own hypothesized relationship between variables with a value of one when there is an expected relationship, and zero when there is no relationship. Then we estimate the parameters of the model and evaluate how well the model describes the observed data.
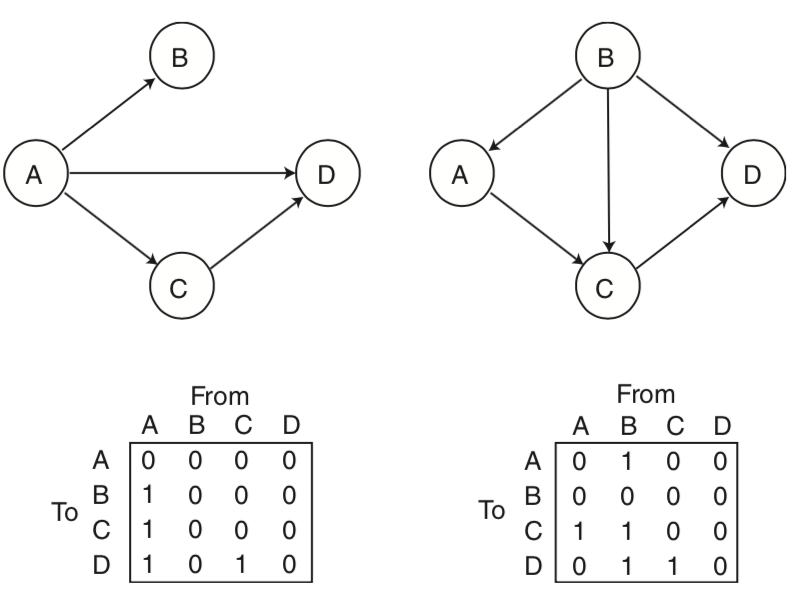
We will not be discussing this method in much detail. In practice, this method is more routinely used to examine how brain activations mediate relationships between other regions, or between different psychological constructs (e.g., X -> Z -> Y).
Here are a couple of videos specifically examining how to conduct mediation and moderation analyses from Principles of fMRI (Mediation and Moderation Part I, Mediation and Moderation Part II)
Granger Causality#
Granger causality was originally developed in econometrics and is used to determine temporal causality. The idea is to quantify how past values of one brain region predict the current value of another brain region. This analysis can also be performed in the frequency domain using measures of coherence between two regions. In general, this technique is rarely used in fMRI data analysis as it requires making assumptions that all regions have the same hemodynamic response function (which does not seem to be true), and that the relationship is stationary, or not varying over time.
Here is a video from Principles of fMRI explaining Granger Causality in more detail.
Dynamic Causal Modeling#
Dynamic Causal Modeling (DCM) is a method specifically developed for conducting causal analyses between regions of the brain for fMRI data. The key innovation is that the developers of this method have specified a generative model for how neuronal firing will be reflected in observed BOLD activity. This addresess one of the problems with SEM, which assumes that each ROI has the same hemodynamic response.
In practice, DCM is computationally expensive to estimate and researchers typically specify a couple small models and perform a model comparison (e.g., bayesian model comparison) to determine, which model best explains the data from a set of proposed models.
Here is a video from Principles of fMRI explaining Dynamic Causal Modeling in more detail.
Multivariate Decomposition#
So far we have discussed functional connectivity in terms of pairs of regions. However, voxels are most likely not independent from each other and we may want to figure out some latent spatial components that are all functionally connected with each (i.e., covary similarly in time).
To do this type of analysis, we typically use what are called multivariate decomposition methods, which attempt to factorize a data set (i.e., time by voxels) into a lower dimensional set of components, where each has their own unique time course.
The most common decomposition methods or Principal Components Analysis (PCA) and Independent Components Analysis (ICA). You may recall that we have already played with ICA in the beginning of the course in the Separating Signal From Noise With ICA lab.
Let’s learn more about the details of decomposition by watching a short video by Martin Lindquist.
from IPython.display import YouTubeVideo
YouTubeVideo('Klp-8t5GLEg')
Principal Components Analysis#
Principal Components Analysis (PCA) is a multivariate procedure that attempts to explain the variance-covariance structure of a high dimensional random vector. In this procedure, a set of correlated variables are transformed int a set of uncorrelated variables, ordered by the amount of variance in the data that they explain.
In fMRI, we use PCA to find spatial maps or eigenimages in the data. This is usually computed using Singular Value Decomposition (SVD). This operation is defined as:
\(X = USV^T\), where \(V^T V = I\), \(U^T U = I\), and \(S\) is a diagonal matrix whose elements are called singular values.
In practice, \(V\) corresponds to the eigenimages or spatial components and \(U\) corresponds to the transformation matrix to convert the eigenimages into a timecourse. \(S\) reflects the amount of scaling for each component.
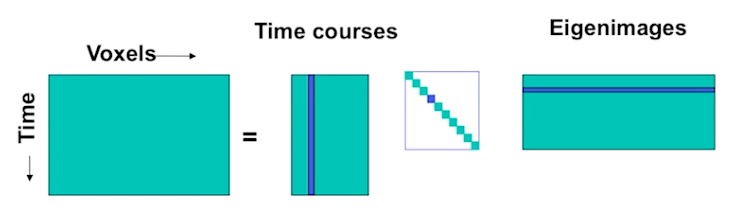
SVD is conceptually very similar to regression. We are trying to explain a matrix \(X\) as a linear combination of components. Each term in the equation reflects a unique (i.e., orthogonal) multivariate signal present in \(X\). For example, the \(nth\) signal in X can be described by the dot product of a time course \(u_n\) and the spatial map \(Vn^T\) scaled by \(s_n\).
\(X = s_1 u_1 v_1^T + s_2 u_2 v_2^T + s_n u_n v_n^T\)
Let’s try running a PCA on our single subject data.
First, let’s denoise our data using a GLM comprised only of nuisance regressors. We will then work with the residual of this model, or what remains of our data that was not explained by the denoising model. This is essentially identical to the vmPFC analysis, except that we will not be including any seed regressors. We will then be working with the residual of our regression, which is the remaining signal after removing any variance associated with our covariates.
csf_mask = Brain_Data(os.path.join(base_dir, 'masks', 'csf.nii.gz'))
csf = zscore(pd.DataFrame(smoothed.extract_roi(mask=csf_mask).T, columns=['csf']))
spikes = smoothed.find_spikes(global_spike_cutoff=3, diff_spike_cutoff=3)
covariates = pd.read_csv(layout.get(subject=sub, scope='derivatives', extension='.tsv')[0].path, sep='\t')
mc = covariates[['trans_x','trans_y','trans_z','rot_x', 'rot_y', 'rot_z']]
mc_cov = make_motion_covariates(mc, tr)
dm = Design_Matrix(pd.concat([vmpfc, csf, mc_cov, spikes.drop(labels='TR', axis=1)], axis=1), sampling_freq=1/tr)
dm = dm.add_poly(order=2, include_lower=True)
smoothed.X = dm
stats = smoothed.regress()
smoothed_denoised=stats['residual']
Now let’s run a PCA on this participant’s denoised data. To do this, we will use the .decompose() method from nltools. All we need to do is specify the algorithm we want to use, the dimension we want to reduce (i.e., time - ‘images’ or space ‘voxels’), and the number of components to estimate. Usually, we will be looking at reducing space based on similarity in time, so we will set axis='images'.
n_components = 10
pca_stats_output = smoothed_denoised.decompose(algorithm='pca', axis='images', n_components=n_components)
Now let’s inspect the components with our interactive component viewer. Remember the ICA tutorial? Hopefully, you are now better able to understand everything.
component_viewer(pca_stats_output, tr=layout.get_tr())
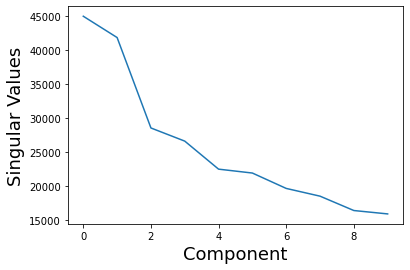
We can also examine the eigenvalues/singular values or scaling factor of each, which are the diagonals of \(S\).
These values are stored in the 'decomposition_object' of the stats_output and are in the variable called .singular_values_.
plt.plot(pca_stats_output['decomposition_object'].singular_values_)
plt.xlabel('Component', fontsize=18)
plt.ylabel('Singular Values', fontsize=18)
Text(0, 0.5, 'Singular Values')
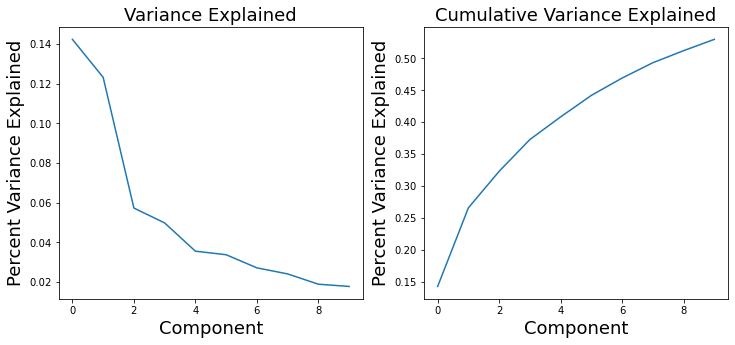
We can use these values to calculate the overall variance explained by each component. These values are stored in the 'decomposition_object' of the stats_output and are in the variable called .explained_variance_ratio_.
These values can be used to create what is called a scree plot to figure out the percent variance of \(X\) explained by each component. Remember, in PCA, components are ordered by descending variance explained.
f,a = plt.subplots(ncols=2, figsize=(12, 5))
a[0].plot(pca_stats_output['decomposition_object'].explained_variance_ratio_)
a[0].set_ylabel('Percent Variance Explained', fontsize=18)
a[0].set_xlabel('Component', fontsize=18)
a[0].set_title('Variance Explained', fontsize=18)
a[1].plot(np.cumsum(pca_stats_output['decomposition_object'].explained_variance_ratio_))
a[1].set_ylabel('Percent Variance Explained', fontsize=18)
a[1].set_xlabel('Component', fontsize=18)
a[1].set_title('Cumulative Variance Explained', fontsize=18)
Text(0.5, 1.0, 'Cumulative Variance Explained')
Independent Components Analysis#
Independent Components Analysis (ICA) is a method to blindly separate a source signal into spatially independent components. This approach assumes that the data consts of \(p\) spatially independent components, which are linearly mixed and spatially fixed. PCA assumes orthonormality constraint, while ICA only assumes independence.
\(X = AS\), where \(A\) is the mixing matrix and \(S\) is the source matrix
In ICA we find an un-mixing matrix \(W\), such that \(Y = WX\) provides an approximation to \(S\). To estimate the mixing matrix, ICA assumes that the sources are (1) linearly mixed, (2) the components are statistically independent, and (3) the components are non-Gaussian.
It is trivial to run ICA on our data as it only requires switching algorithm='pca' to algorithm='ica' when using the decompose() method.
We will experiment with this in our exercises.
We also encourage interested readers to check out our more in depth ICA tutorial.
Graph Theory#
Similar to describing the structure of social networks, graph theory has also been used to characterize regions of the brain based on how they connected to other regions. Nodes in the network typically describe specific brain regions and edges represent the strength of the association between each edge. That is, the network can be represented as a graph of pairwise relationships between each region of the brain.
There are many different metrics of graphs that can be used to describe the overall efficiency of a network (e.g., small worldness), or how connected a region is to other regions (e.g., degree, centrality), or how long it would take to send information from one node to another node (e.g., path length, connectivity).
Let’s watch a short video by Martin Lindquist providing a more in depth introduction to graph theory.
YouTubeVideo('v8ls5VED1ng')
Suppose, we were interested in identifying which regions of the brain had the highest degree of centrality based on functional connectivity. There are many different ways to do this, but they all involve specifying a set of nodes (i.e., ROIs) and calculating the edges between each node. Finally, we would need to pick a centrality metric and calculate the overall level of centrality for each region.
Let’s do this quickly building off of our seed-based functional connectivity analysis.
Similar, to the PCA example, let’s work with the denoised data. First, let’s extract the average time course within each ROI from our 50 parcels and plot the results.
rois = smoothed_denoised.extract_roi(mask=mask)
plt.figure(figsize=(15,5))
plt.plot(rois.T)
plt.ylabel('Mean Intensitiy', fontsize=18)
plt.xlabel('Time (TRs)', fontsize=18)
Text(0.5, 0, 'Time (TRs)')
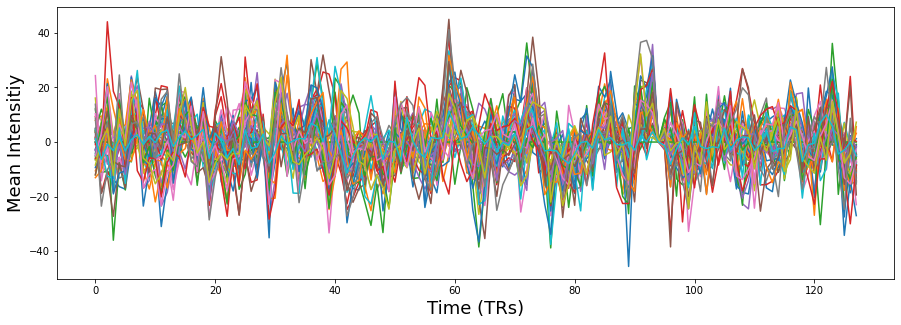
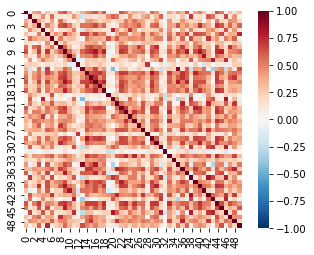
Now that we have specified our 50 nodes, we need to calculate the edges of the graph. We will be using pearson correlations. We will be using the pairwise_distances function from scikit-learn as it is much faster than most other correlation measures. We will then convert the distance metric into similarities by subtracting all of the values from 1.
Let’s visualize the resulting correlation matrix as a heatmap using seaborn.
roi_corr = 1 - pairwise_distances(rois, metric='correlation')
sns.heatmap(roi_corr, square=True, vmin=-1, vmax=1, cmap='RdBu_r')
<AxesSubplot:>
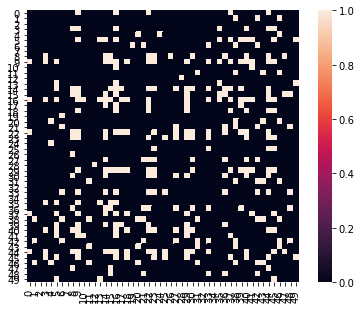
Now we need to convert this correlation matrix into a graph and calculate a centrality measure. We will use the Adjacency class from nltools as it has many functions that are useful for working with this type of data, including casting these type of matrices into networkx graph objects.
We will be using the networkx python toolbox to work with graphs and compute different metrics of the graph.
Let’s calculate degree centrality, which is the total number of nodes each node is connected with. Unfortunately, many graph theory metrics require working with adjacency matrices, which are binary matrices indicating the presence of an edge or not. To create this, we will simply apply an arbitrary threshold to our correlation matrix.
a = Adjacency(roi_corr, matrix_type='similarity', labels=[x for x in range(50)])
a_thresholded = a.threshold(upper=.6, binarize=True)
a_thresholded.plot()
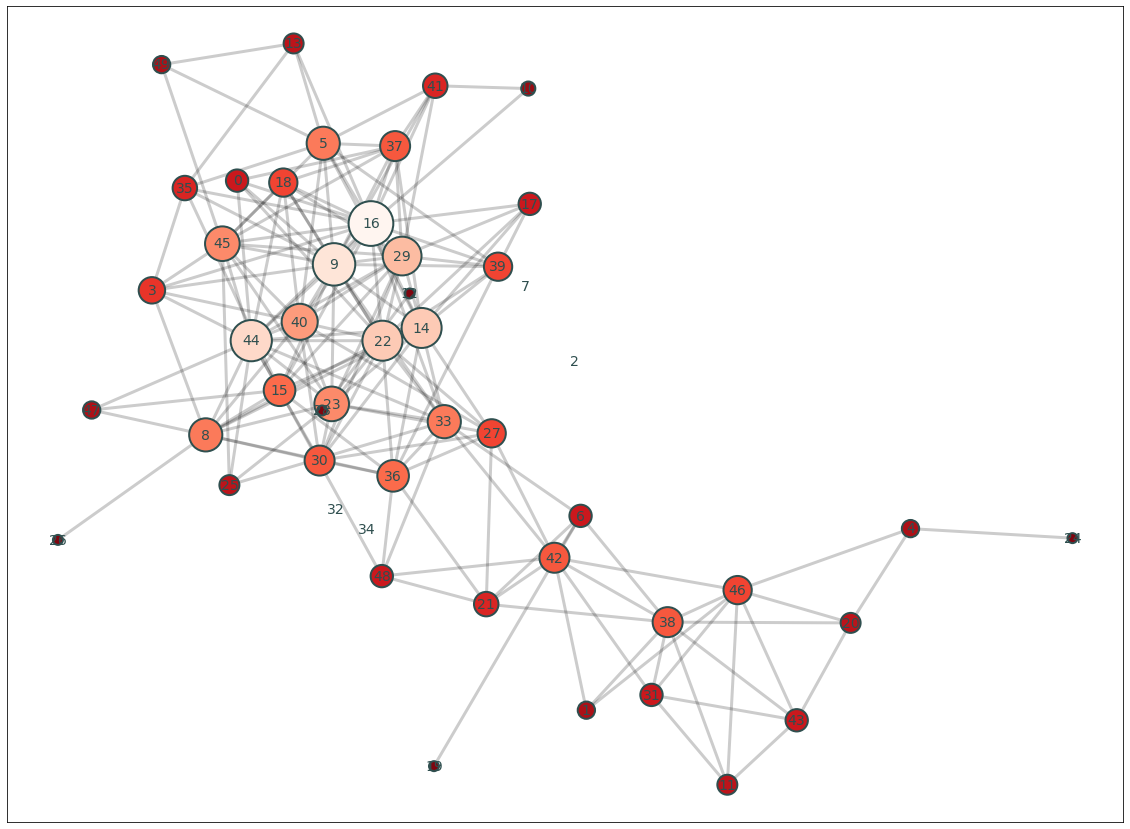
Okay, now that we have a thresholded binary matrix, let’s cast our data into a networkx object and calculate the degree centrality of each ROI and make a quick plot of the graph.
plt.figure(figsize=(20,15))
G = a_thresholded.to_graph()
pos = nx.kamada_kawai_layout(G)
node_and_degree = G.degree()
nx.draw_networkx_edges(G, pos, width=3, alpha=.2)
nx.draw_networkx_labels(G, pos, font_size=14, font_color='darkslategray')
nx.draw_networkx_nodes(G, pos, nodelist=list(dict(node_and_degree).keys()),
node_size=[x[1]*100 for x in node_and_degree],
node_color=list(dict(node_and_degree).values()),
cmap=plt.cm.Reds_r, linewidths=2, edgecolors='darkslategray', alpha=1)
<matplotlib.collections.PathCollection at 0x7facb0faf810>
We can also plot the distribution of degree using this threshold.
plt.hist(dict(G.degree).values())
plt.ylabel('Frequency', fontsize=18)
plt.xlabel('Degree', fontsize=18)
Text(0.5, 0, 'Degree')
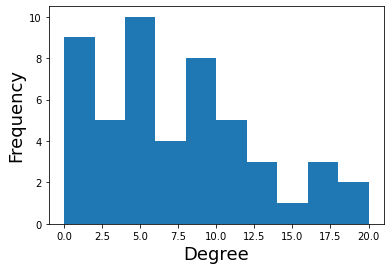
What if we wanted to map the degree of each node back onto the brain?
This would allow us to visualize which of the parcels had more direct pairwise connections.
To do this, we will simply scale our expanded binary mask object by the node degree. We will then combine the masks by concatenating through recasting as a brain_data object and then summing across all ROIs.
degree = pd.Series(dict(G.degree()))
brain_degree = roi_to_brain(degree, mask_x)
brain_degree.plot()

view_img_on_surf(brain_degree.to_nifti())
This analysis shows that the insula is one of the regions that appears to have the highest degree in this analysis. This is a fairly classic finding with the insula frequently found to be highly connected with other regions. Of course, we are only looking at one subject in a very short task (and selecting a completely arbitrary cutoff). We would need to show this survives correction after performing a group analysis.
Exercises#
Let’s practice what we learned through a few different exercises.
1) Let’s calculate seed-based functional connectivity using a different ROI - the right motor cortex#
Calculate functional connectivity using roi=48 with the whole brain.
2) Calculate a group level analysis for this connectivity analysis#
this will require running this analysis over all subjects
then running a one sample t-test
then correcting for multiple tests with fdr.
3) Calculate an ICA#
run an ICA analysis for subject01 with 5 components
plot each spatial component and its associated timecourse
4) Calculate Eigenvector Centrality for each Region#
figure out how to calculate eigenvector centrality and compute it for each region.
5) Calculate a group level analysis for this graph theoretic analysis#
this will require running this analysis over all subjects
then running a one sample t-test
then correcting for multiple tests with fdr.