Group Analysis#
Written by Luke Chang
In fMRI analysis, we are primarily interested in making inferences about how the brain processes information that is fundamentally similar across all brains even for people that did not directly participate in our study. This requires making inferences about the magnitude of the population level brain response based on measurements from a few randomly sampled participants who were scanned during our experiment.
In this tutorial, we will cover how we go from modeling brain responses in each voxel for a single participant to making inferences about the group. We will cover the following topics:
Mixed Effects Models
How to use the summary statistic approach to make inferences at second level
How to perform many types of inferences at second level with different types of design matrics
Let’s start by watching an overview of group statistics by Tor Wager.
from IPython.display import YouTubeVideo
YouTubeVideo('__cOYPifDWk')
Hierarchical Data Structure#
We can think of the data as being organized into a hierarchical structure. For each brain, we are measuring BOLD activity in hundreds of thousands of cubic voxels sampled at about 0.5Hz (i.e., TR=2s). Our experimental task will have many different trials for each condition (seconds), and these trials may be spread across multiple scanning runs (minutes), or entire scanning sessions (hours). We are ultimately interested in modeling all of these different scales of data to make an inference about the function of a particular region of the brain across the group of participants we sampled, which we would hope will generalize to the broader population.
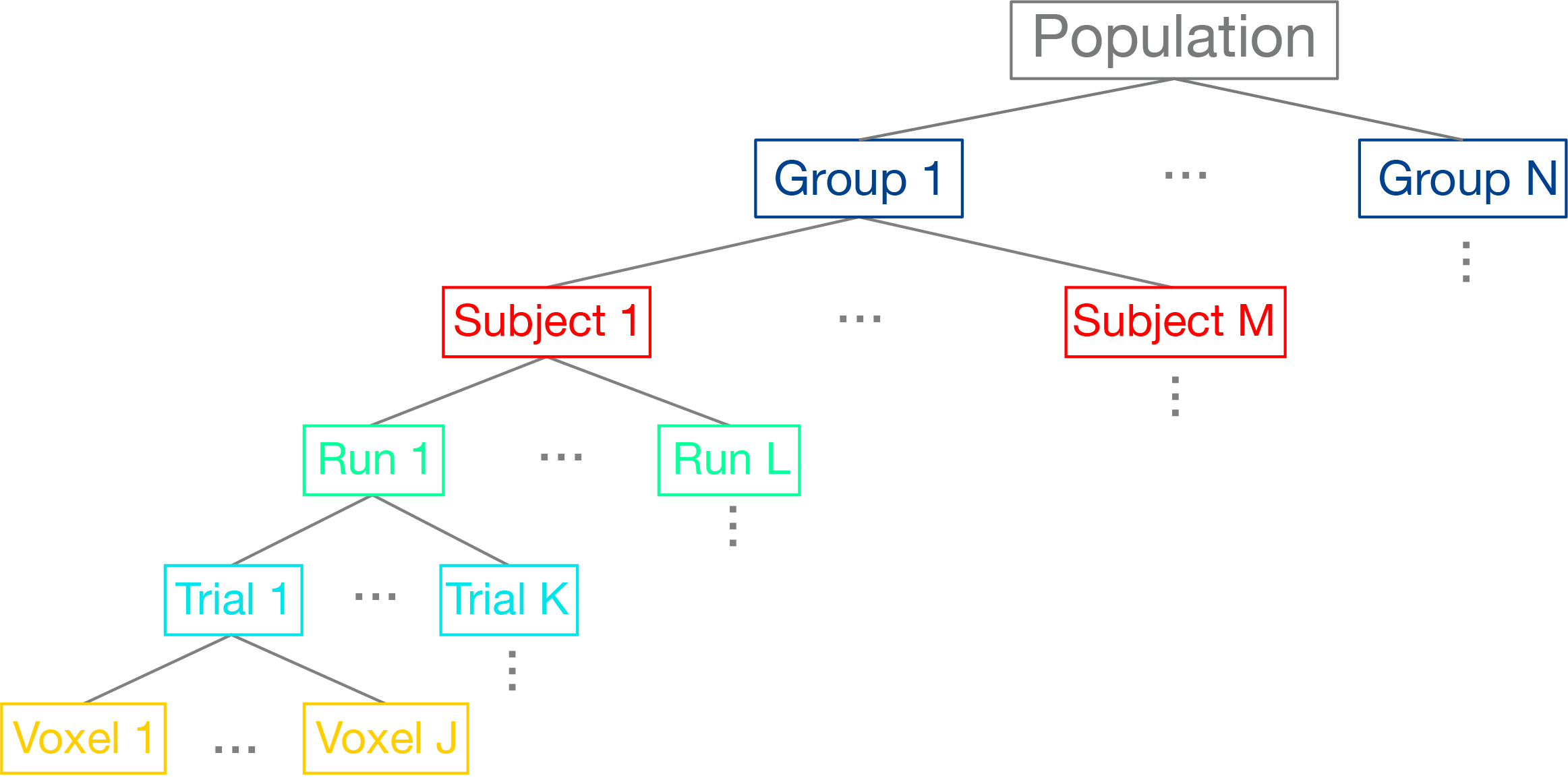
In the past few notebooks, we have explored how to preprocess the data to reduce noise and enhance our signal and also how we can estimate responses in each voxel to specific conditions within a single participant based on convolving our experimental design with a canonical hemodynamic response function (HRF). Here we will discuss how we combine these brain responses estimated at the first-level in a second-level model to make inferences about the group.
Modeling Mixed Effects#
Let’s dive deeper into how we can model both random and fixed effects using multi-level models by watching another video by Tor Wager.
YouTubeVideo('-abMLQSjMSI')
Most of the statistics we have discussed to this point have assumed that the data we are trying to model are drawn from an identical distribution and that they are independent of each other. For example, each group of participants that complete each version of our experiment are assumed to be random sample of the larger population. However, if there was some type of systematic bias in our sampling strategy, our group level statistics would not necessarily reflect a random draw from the population-level Gaussian distribution. However, as should already be clear from the graphical depiction of the hierarchical structure of our data above, our data are not always independent. For example, we briefly discussed this in the GLM notebook, but voxel responses within the same participant are not necessarily independent as there appears to be a small amount of autocorrelation in the BOLD response. This requires whitening the data to meet the independence assumption. What is clear from the hierarchy is that all of the data measured from one participant are likely to be more similar to each other than another participant. In fact, it is almost always the case that the variance within a subject \(\sigma_{within}^2\) is almost always smaller than the variance across participants \(\sigma_{between}^2\). If we combined all of the data from all participants and treated them as if they were independent, we would likely have an inflated view of the group effect (this was historically referred to as a “fixed effects group analysis”).
This problem has been elegantly solved in statistics in a class of models called mixed effects models. Mixed effects models are an extension of regression that allows data to be structured into groups and coefficients to vary by groups. They are referred to differently in different scientific domains, for example they may be referred to as multilevel, hierarchical, or panel models. The reason that this framework has been found to be useful in many different fields, is that it is particularly well suited for modeling clustered data, such as students in a classroom and also longitudinal or repeated data, such as within-subject designs.
The term “mixed” comes from the fact that these models are composed of both fixed and random effects. Fixed effects refer to parameters describing the amount of variance that a feature explains of an outcome variable. Fixed factors are often explicitly manipulated in an experiment and can be categorical (e.g., gender) or continuous (e.g., age). We assume that the magnitude of these effects are fixed in the population, but that the observed signal strength will vary across sessions and subjects. This variation can be decomposed into different sources of variance, such as: - Measurement or Irreducible Error - Response magnitude that varies randomly across subjects. - Response magnitude that varies randomly across different elicitations (e.g., trials or sessions).
Modeling these different sources of variance allows us to have a better idea of how generalizable our estimates might be to another participant or trial.
As an example, imagine if we were interested if there were any gender differences between the length of how males and females cut their hair. We might sample a given individual several times over the course of a couple of years to get an accurate measurement of how long they keep their hair. These samples are akin to trials and will give us a way to represent the overall tendency of the length an individual keeps their hair in the form of a distribution. Narrow distributions mean that there is little variability in the length of the hair at each measurement, while wider distributions indicate more variation in the hair length across time. Of course, we are most interested not in the length of how an individual cuts their hair, but rather how many individuals from the same group cut their hair. This requires measuring multiple participants, who will all vary randomly around some population level hair length parameter. We are interested in modeling the true fixed effect of what the population parameter is for hair length, and specifically, whether this differs across gender. The variation in measurements within an individual and across individuals will reflect some degree of randomness that we need to account for in order to estimate a parameter that will generalize beyond the participants we measured their hair, but to new participants.
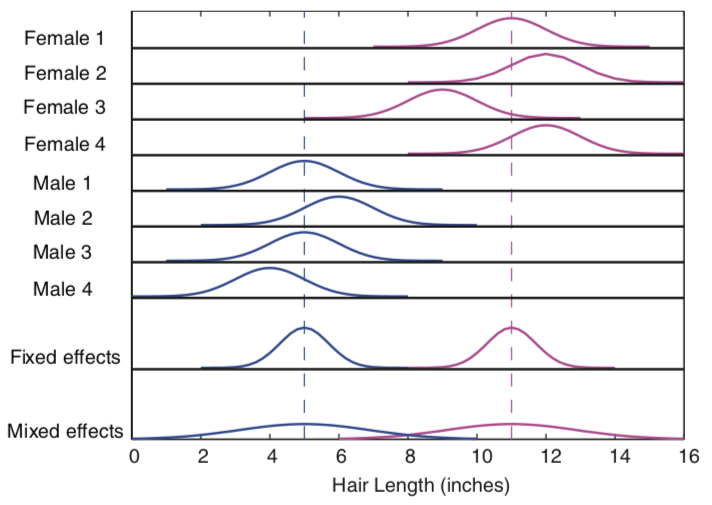 from Poldrack, Mumford, & Nichols (2011)
from Poldrack, Mumford, & Nichols (2011)
In statistics, it is useful to distinguish between the model used to describe the data, the method of parameter estimation, and the algorithm used to obtain them.
Let’s now watch a video by Martin Lindquist to learn more about the way these models are estimated.
YouTubeVideo('-yaHTygR9b8')
First Level - Single Subject Model#
In fMRI data analysis, we often break analyses into multiple stages. First, we are interested in estimating the parameter (or distribution) of signal in a given region resulting from our experimental manipulation, while simultaneously attempting to control for as much noise and artifacts as possible. This will give us a a single number for each participant of the average length they keep their hair.
At the first level model, for each participant we can define our model as:
\(Y_i = X_i\beta + \epsilon_i\), where \(i\) is an observation for a single participant and \(\epsilon_i \sim \mathcal{N}(0, \sigma_i^2)\)
Because participants are independent, it is possible to estimate each participant separately.
To provide a concrete illustration of the different sources of variability in a signal, let’s make a quick simulation a hypothetical voxel timeseries.
%matplotlib inline
import os
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from nltools.stats import regress, zscore
from nltools.data import Brain_Data, Design_Matrix
from nltools.stats import regress
from nltools.external import glover_hrf
from scipy.stats import ttest_1samp
def plot_timeseries(data, linewidth=3, labels=None, axes=True):
f,a = plt.subplots(figsize=(20,5))
a.plot(data, linewidth=linewidth)
a.set_ylabel('Intensity', fontsize=18)
a.set_xlabel('Time', fontsize=18)
plt.tight_layout()
if labels is not None:
plt.legend(labels, fontsize=18)
if not axes:
a.axes.get_xaxis().set_visible(False)
a.axes.get_yaxis().set_visible(False)
def simulate_timeseries(n_tr=200, n_trial=5, amplitude=1, tr=1, sigma=0.05):
y = np.zeros(n_tr)
y[np.arange(20, n_tr, int(n_tr/n_trial))] = amplitude
hrf = glover_hrf(tr, oversampling=1)
y = np.convolve(y, hrf, mode='same')
epsilon = sigma*np.random.randn(n_tr)
y = y + epsilon
return y
sim1 = simulate_timeseries(sigma=0)
sim2 = simulate_timeseries(sigma=0.05)
plot_timeseries(np.vstack([sim1,sim2]).T, labels=['Signal', 'Noisy Signal'])
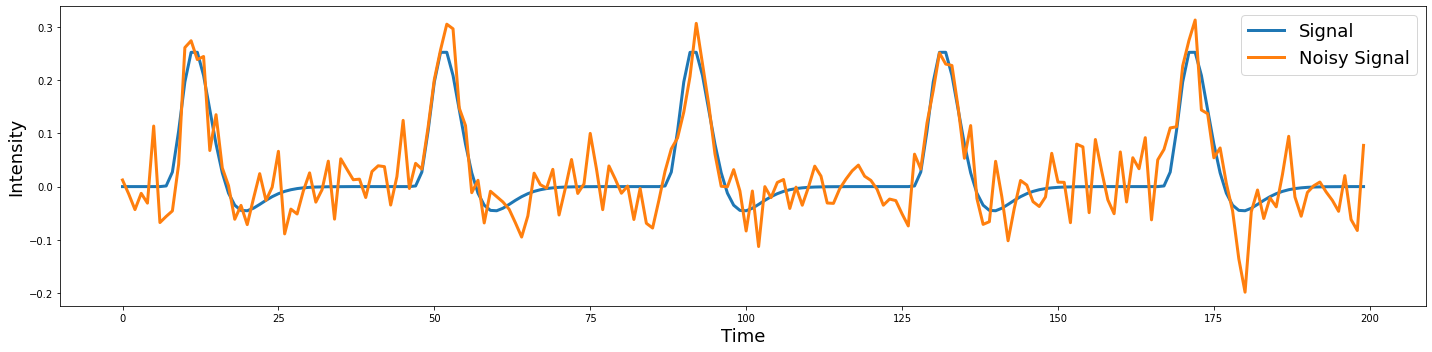
Notice that the noise appears to be independent over each TR.
Second level summary of between group variance#
In the second level model, we are interested in relating the subject specific parameters contained in \(\beta\) to the population parameters \(\beta_g\). We assume that the first level parameters are randomly sampled from a population of possible regression parameters.
\(\beta = X_g\beta_g + \eta\)
\(\eta \sim \mathcal{N}(0,\,\sigma_g^{2})\)
Now let’s add noise onto the beta parameter to see what happens.
beta = np.abs(np.random.randn())*3
sim1 = simulate_timeseries(sigma=0)
sim2 = simulate_timeseries(sigma=0.05)
sim3 = simulate_timeseries(amplitude=beta, sigma=0.05)
plot_timeseries(np.vstack([sim1,sim2,sim3]).T, labels=['Signal', 'Noisy Signal', 'Noisy Beta + Noisy Signal'])
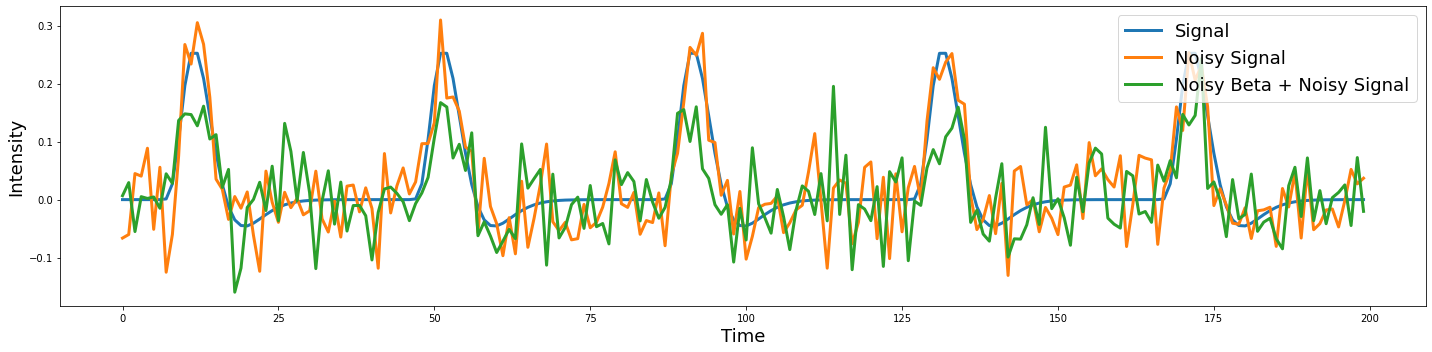
Try running the above code several times. Can you see how the beta parameter impacts the amplitude of each trial, while the noise appears to be random and uncorrelated with the signal?
Let’s try simulating three subjects with a beta drawn from a normal distribution.
sim1 = simulate_timeseries(amplitude=np.abs(np.random.randn())*2, sigma=0.05)
sim2 = simulate_timeseries(amplitude=np.abs(np.random.randn())*2, sigma=0.05)
sim3 = simulate_timeseries(amplitude=np.abs(np.random.randn())*2, sigma=0.05)
plot_timeseries(np.vstack([sim1, sim2, sim3]).T, labels=['Subject 1', 'Subject 2', 'Subject 3'])
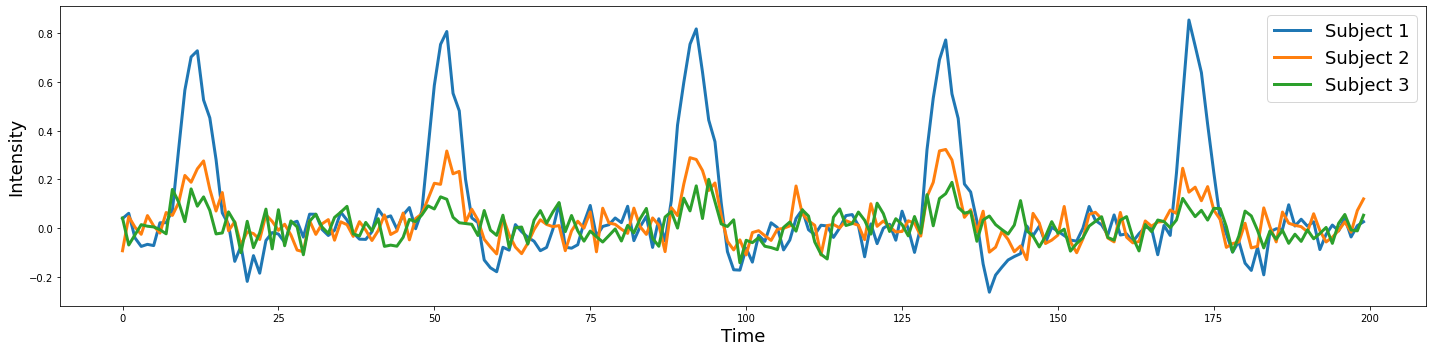
To make an inference if there is a reliable difference within or across groups, we need to model the distribution of the parameters resulting from the first level model using a second level model. For example, if we were solely interested in estimating the average length men keep their hair, we would need to measure hair lengths from lots of different men and the average would be our best guess for any new male sampled from the same population. In our example, we are explicitly interested in the pairwise difference between males and females in hair length. Does the mean hair length for one sex significantly different from the hair length of the other group that is larger than the variations in hair length we observe within each group?
Mixed Effects Model#
In neuroimaging data analysis, there are two main approaches to implementing these different models. Some software packages attempt to use a computationally efficient approximation and use what is called a two stage summary statistic approach. First level models are estimated separately for every participant and then the betas from each participant’s model is combined in a second level model. This is the strategy implemented in SPM and is computationally efficient. However, another approach simultaneously estimates the first and second level models at the same time and often use algorithms that iterate back and forth from the single to the group. The main advantage of this approach over the two-stage approach is that the uncertainty in the parameter estimates at the first-level can be appropriately weighted at the group level. For example, if we had a bad participant with very noisy data, we might not want to weight their estimate when we aggregate everyone’s data across the group. The disadvantage of this approach is that the estimation procedure is considerably more computationally expensive. This is the approach implemented in FSL, BrainVoyager, and AFNI. In practice, the advantage of the true random effects simultaneous parameter estimation only probably benefits getting more reliable estimates when the sample size is small. In the limit, both methods should converge to the same answer. For a more in depth comparison see this blog post by Eshin Jolly.
A full mixed effects model can be written as,
or
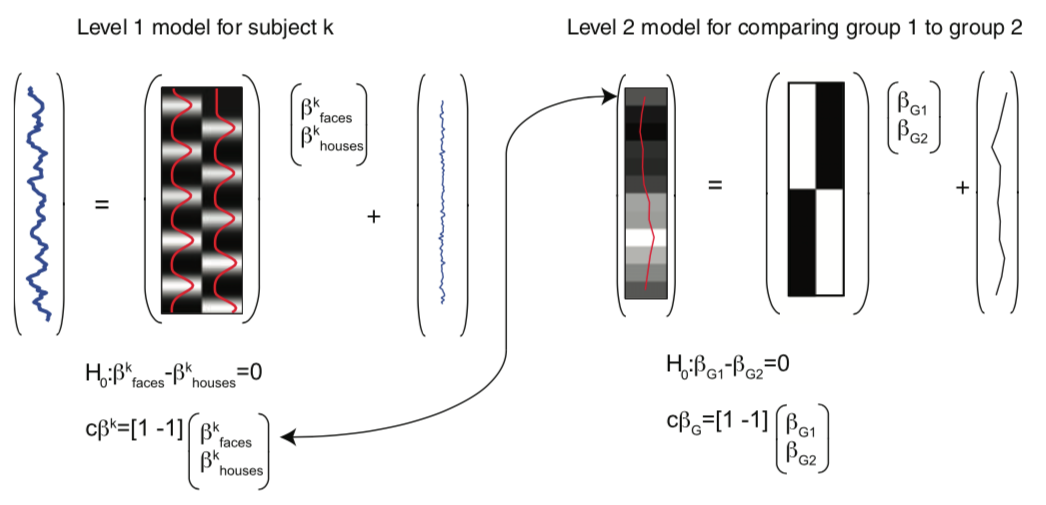
from Poldrack, Mumford, & Nichols (2011)
Let’s now try to recover the beta estimates from our 3 simulated subjects.
# Create a design matrix with an intercept and predicted response
task = simulate_timeseries(amplitude=1, sigma=0)
X = np.vstack([np.ones(len(task)), task]).T
# Loop over each of the simulated participants and estimate the amplitude of the response.
betas = []
for sub in [sim1, sim2, sim3]:
beta,_,_,_,_,_ = regress(X, sub)
betas.append(beta[1])
# Plot estimated amplitudes for each participant
plt.bar(['Subject1', 'Subject2', 'Subject3'], betas)
plt.ylabel('Estimated Beta', fontsize=18)
Text(0, 0.5, 'Estimated Beta')
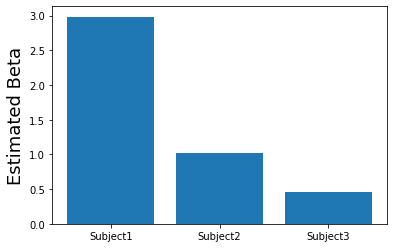
What if we simulated lots of participants? What would the distribution of betas look like?
# Create a design matrix with an intercept and predicted response
task = simulate_timeseries(amplitude=1, sigma=0)
X = np.vstack([np.ones(len(task)), task]).T
# Loop over each of the simulated participants and estimate the amplitude of the response.
betas = []
for sub in range(100):
sim = simulate_timeseries(amplitude=2+np.random.randn()*2, sigma=0.05)
beta,_,_,_,_,_ = regress(X, sim)
betas.append(beta[1])
# Plot distribution of estimated amplitudes for each participant
plt.hist(betas)
plt.ylabel('Frequency', fontsize=18)
plt.xlabel('Estimated Beta', fontsize=18)
plt.axvline(x=0, color='r', linestyle='dashed', linewidth=2)
<matplotlib.lines.Line2D at 0x7f990c25ced0>
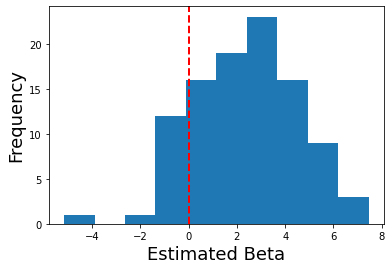
Now in a second level analysis, we are interested in whether there is a reliable effect across all participants in our sample. In other words, is there a response to our experiment for a specific voxel that is reliably present across our sample of participants?
We can test this hypothesis in our simulation by running a one-sample ttest across the estimated first-level betas at the second level. This allows us to test whether the sample has signal that is reliably different from zero (i.e., the null hypothesis).
ttest_1samp(betas, 0)
Ttest_1sampResult(statistic=10.854776909716737, pvalue=1.50775361636617e-18)
What did we find?
Running a Group Analysis#
Okay, now let’s try and run our own group level analysis with real imaging data using the Pinel Localizer data. I have run a first level model for the first 10 participants using the procedure we used in the single-subject analysis notebook.
Here is the code I used to complete this for all participants. I wrote all of the betas and also a separate file for each individual regressor of interest.
import os
from glob import glob
from tqdm import tqdm
import pandas as pd
import numpy as np
import nibabel as nib
from nltools.stats import zscore, regress, find_spikes
from nltools.data import Brain_Data, Design_Matrix
from bids import BIDSLayout, BIDSValidator
from nltools.file_reader import onsets_to_dm
from nltools.data import Brain_Data, Design_Matrix
from nilearn.plotting import view_img, glass_brain, plot_stat_map
data_dir = '../data/localizer'
layout = BIDSLayout(data_dir, derivatives=True)
tr = layout.get_tr()
fwhm = 6
spike_cutoff = 3
def load_bids_events(layout, subject):
'''Create a design_matrix instance from BIDS event file'''
tr = layout.get_RepetitionTime()[0]
n_tr = nib.load(layout.get(subject=subject, scope='derivatives', suffix='bold', return_type='filename', extension='nii.gz')[0]).shape[-1]
onsets = pd.read_csv(layout.get(subject=subject, suffix='events')[0].path, sep='\t')
onsets.columns = ['Onset', 'Duration', 'Stim']
return onsets_to_dm(onsets, sampling_freq=1/tr, run_length=n_tr)
def make_motion_covariates(mc):
z_mc = zscore(mc)
all_mc = pd.concat([z_mc, z_mc**2, z_mc.diff(), z_mc.diff()**2], axis=1)
all_mc.fillna(value=0, inplace=True)
return Design_Matrix(all_mc, sampling_freq=1/tr)
# Create output folder if it doesn't exist yet
if not os.path.exists('../data/localizer/derivatives/betas'):
os.mkdir('../data/localizer/derivatives/betas')
for sub in tqdm(layout.get_subjects(scope='derivatives')):
data = Brain_Data(layout.get(subject=sub, scope='derivatives', suffix='bold', extension='nii.gz', return_type='file')[0])
data = data.smooth(fwhm=fwhm)
dm = load_bids_events(layout, sub)
covariates = pd.read_csv(layout.get(subject=sub, scope='derivatives', extension='.tsv')[0].path, sep='\t')
mc_cov = make_motion_covariates(covariates[['trans_x','trans_y','trans_z','rot_x', 'rot_y', 'rot_z']])
spikes = data.find_spikes(global_spike_cutoff=spike_cutoff, diff_spike_cutoff=spike_cutoff)
dm_cov = dm.convolve().add_dct_basis(duration=128).add_poly(order=1, include_lower=True)
dm_cov = dm_cov.append(mc_cov, axis=1).append(Design_Matrix(spikes.iloc[:, 1:], sampling_freq=1/tr), axis=1)
data.X = dm_cov
stats = data.regress()
# Write out all betas
stats['beta'].write(f'../data/localizer/derivatives/betas/{sub}_betas.nii.gz')
# Write out separate beta for each condition
for i, name in enumerate([x[:-3] for x in dm_cov.columns[:10]]):
stats['beta'][i].write(f'../data/localizer/derivatives/betas/{sub}_beta_{name}.nii.gz')
Now, we are ready to run our first group analyses!
Let’s load our design matrix to remind ourselves of the various conditions
One Sample t-test#
For our first group analysis, let’s try to examine which regions of the brain are consistently activated across participants. We will just load the first regressor in the design matrix - horizontal_checkerboard.
We will use the glob function to search for all files that contain the name horizontal_checkerboard in each subject’s folder. We will then sort the list and load all of the files using the Brain_Data class. This will take a little bit to load all of the data into ram.
import glob
con1_name = 'horizontal_checkerboard'
con1_file_list = glob.glob(os.path.join(data_dir, 'derivatives','fmriprep','*', 'func', f'sub*_{con1_name}*nii.gz'))
con1_file_list.sort()
con1_dat = Brain_Data(con1_file_list)
Now that we have the data loaded, we can run quick operations such as, what is the mean activation in each voxel across participants? Or, what is the standard deviation of the voxel activity across participants?
Notice how we can chain different commands like .mean() and .plot(). This makes it easy to quickly manipulate the data similar to how we use tools like pandas.
con1_dat.mean().plot()
threshold is ignored for simple axial plots

We can use the ttest() method to run a quick t-test across each voxel in the brain.
con1_stats = con1_dat.ttest()
print(con1_stats.keys())
dict_keys(['t', 'p'])
This return a dictionary of a map of the t-values and a separate one containing the p-value for each voxel.
For now, let’s look at the results of the t-ttest and threshold them to something like t>4.
con1_stats['t'].iplot()
As you can see we see very clear activation in various parts of visual cortex, which we expected from the visual stimulation.
However, if wanted to test the hypothesis that there are specific areas of early visual cortex (e.g., V1) that process edge orientations, we could run a specific contrast comparing vertical orientations with horizontal orientations.
Now we need to load the vertical data and create a contrast between horizontal and vertical checkerboards.
Here a contrast is simply [1, -1] and can be achieved by simply subtracting the two images (assuming the subject images are sorted in the same order).
con2_name = 'vertical_checkerboard'
con2_file_list = glob.glob(os.path.join(data_dir, 'derivatives','fmriprep','*', 'func', f'sub*_{con2_name}*nii.gz'))
con2_file_list.sort()
con2_dat = Brain_Data(con2_file_list)
con1_v_con2 = con1_dat-con2_dat
Again, we will now run a one-sample ttest on the contrast to find regions that are consistently different in viewing horizontal vs vertical checkerboards across participants at the group level.
con1_v_con2_stats = con1_v_con2.ttest()
con1_v_con2_stats['t'].iplot()
Group statistics using design matrices#
For these analyses we ran a one-sample t-test to examine the average activation to horizontal checkerboards and the difference between viewing horizontal and vertical checkerboards. This is equivalent to a vector of ones at the second level. The latter analysis is technically a paired-samples t-test.
Do these tests sound familiar?
It turns out that most parametric statistical tests are just special cases of the general linear model. Here are what the design matrices would look like for various types of statistical tests.
 from Poldrack, Mumford, & Nichols 2011
from Poldrack, Mumford, & Nichols 2011
In this section, we will explore how we can formulate different types of statistical tests using a regression through simulations.
One Sample t-test#
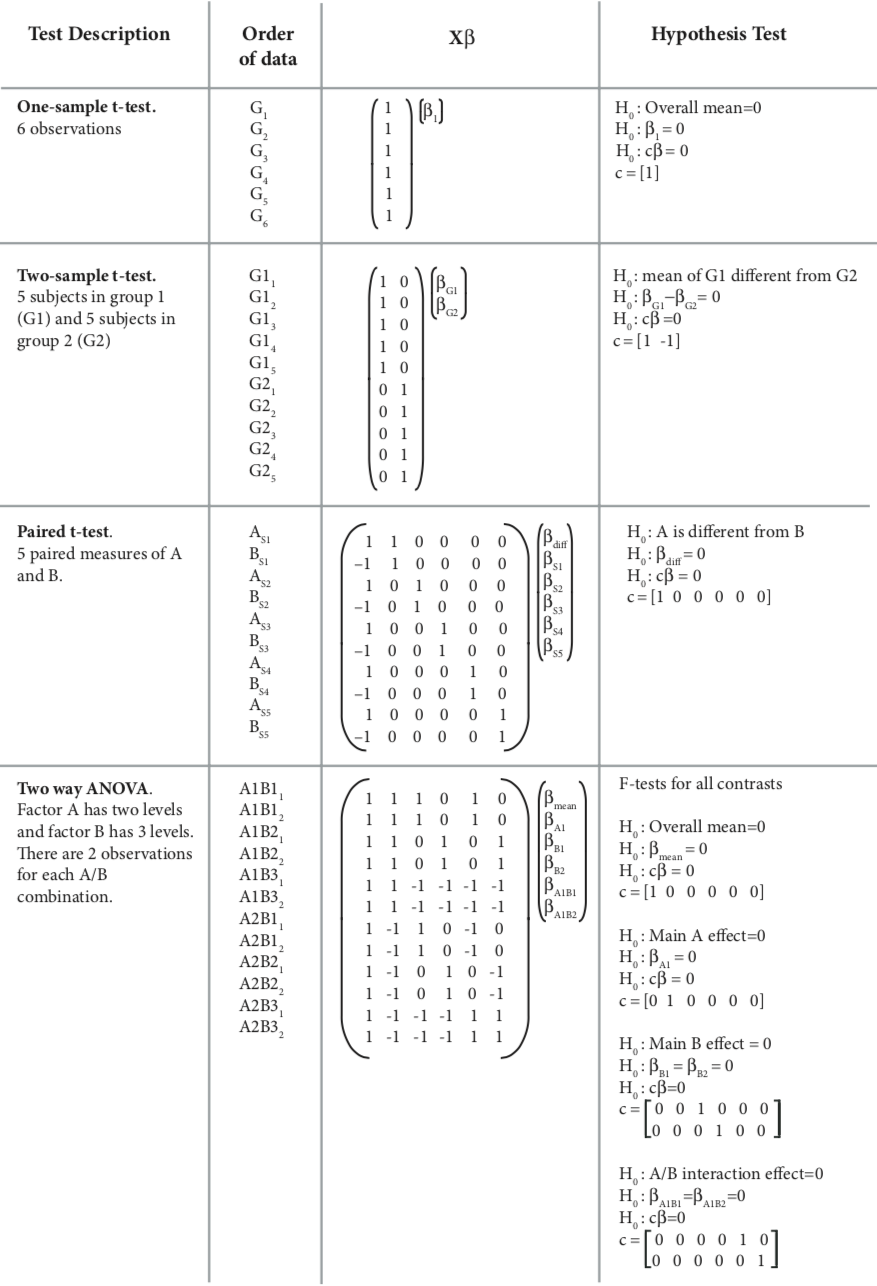
Just to review, our one sample t-test can also be formulated as a regression, where the beta values for each subject in a voxel are predicted by a vector of ones. This intercept only model, computes the mean of \(y\). If the mean of \(y\) (i.e., the intercept) is consistently shifted away from zero, then we can reject the null hypothesis that the mean of the betas is zero.
We can simulate this by generating data from a Gaussian distribution. We will generate two groups, where \(y\) reflects equal draws from each of these distributions \({group_1} = \mathcal{N}(10, 2)\) and \({group_2} = \mathcal{N}(5, 2)\). We then regress a vector of ones on \(y\).
We report the estimated value of beta and compare it to various summaries of the simulated data. This allows us to see exactly what each parameter in the regression is calculating.
First, let’s define a function run_regression_simulation to help us generate plots and calculate various ways to summarize the simulation.
def run_regression_simulation(x, y, paired=False):
'''This Function runs a regression and outputs results'''
# Estimate Regression
if not paired:
b, t, p, df, res = regress(x, y)
print(f"betas: {b}")
if x.shape[1] > 1:
print(f"beta1 + beta2: {b[0] + b[1]}")
print(f"beta1 - beta2: {b[0] - b[1]}")
print(f"mean(group1): {np.mean(group1)}")
print(f"mean(group2): {np.mean(group2)}")
print(f"mean(group1) - mean(group2): {np.mean(group1)-np.mean(group2)}")
print(f"mean(y): {np.mean(y)}")
else:
beta, t, p, df, res = regress(x, y)
a = y[x.iloc[:,0]==1]
b = y[x.iloc[:,0]==-1]
out = []
for sub in range(1, X.shape[1]):
sub_dat = y[X.iloc[:, sub]==1]
out.append(sub_dat-np.mean(sub_dat))
avg_sub_mean_diff = np.mean([x[0] for x in out])
print(f"betas: {b}")
print(f"contrast beta: {beta[0]}")
print(f"mean(subject betas): {np.mean(beta[1:])}")
print(f"mean(y): {np.mean(y)}")
print(f"mean(a): {a.mean()}")
print(f"mean(b): {b.mean()}")
print(f"mean(a-b): {np.mean(a - b)}")
print(f"sum(a_i-mean(y_i))/n: {avg_sub_mean_diff}")
# Create Plot
f,a = plt.subplots(ncols=2, sharey=True)
sns.heatmap(pd.DataFrame(y), ax=a[0], cbar=False, yticklabels=False, xticklabels=False)
sns.heatmap(x, ax=a[1], cbar=False, yticklabels=False)
a[0].set_ylabel('Subject Values', fontsize=18)
a[0].set_title('Y')
a[1].set_title('X')
plt.tight_layout()
okay, now let’s run the simulation for the one sample t-test.
group1_params = {'n':20, 'mean':10, 'sd':2}
group2_params = {'n':20, 'mean':5, 'sd':2}
group1 = group1_params['mean'] + np.random.randn(group1_params['n']) * group1_params['sd']
group2 = group2_params['mean'] + np.random.randn(group2_params['n']) * group2_params['sd']
y = np.hstack([group1, group2])
x = pd.DataFrame({'Intercept':np.ones(len(y))})
run_regression_simulation(x, y)
betas: 7.767465428733612
mean(y): 7.767465428733613
The results of this simulation clearly demonstrate that the intercept of the regression is modeling the mean of \(y\).
Independent-Samples T-Test - Dummy Codes#
Next, let’s explore how we can compute an independent-sample t-test using a regression. There are several different ways to compute this. Each of them provides a different way to test for differences between the means of the two samples.
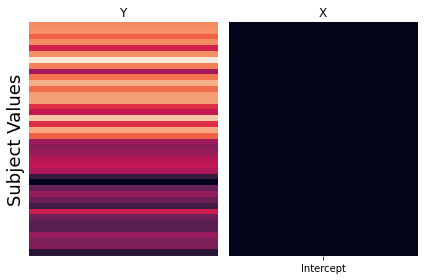
First, we will explore how dummy codes can be used to test for group differences. We will create a design matrix with an intercept and also a column with a binary regressor indicating group membership. The target group will be ones, and the reference group will be zeros.
Let’s run another simulation examining what the regression coefficients reflect using this dummy code approach.
group1_params = {'n':20, 'mean':10, 'sd':2}
group2_params = {'n':20, 'mean':5, 'sd':2}
group1 = group1_params['mean'] + np.random.randn(group1_params['n']) * group1_params['sd']
group2 = group2_params['mean'] + np.random.randn(group2_params['n']) * group2_params['sd']
y = np.hstack([group1, group2])
x = pd.DataFrame({'Intercept':np.ones(len(y)), 'Contrast':np.hstack([np.ones(group1_params['n']), np.zeros(group2_params['n'])])})
run_regression_simulation(x, y)
betas: [5.59590636 4.86905406]
beta1 + beta2: 10.46496042000535
beta1 - beta2: 0.7268523061306578
mean(group1): 10.464960420005351
mean(group2): 5.595906363068004
mean(group1) - mean(group2): 4.869054056937347
mean(y): 8.030433391536677

Can you figure out what the beta estimates are calculating?
The intercept \(\beta_0\) is now the mean of the reference group, and the estimate of the dummy code regressor \(\beta_1\) indicates the difference of the mean of the target group from the reference group.
Thus, the mean of the reference group is \(\beta_0\) or the intercept, and the mean of the target group is \(\beta_1 + \beta_2\).
Independent-Samples T-Test - Contrasts#
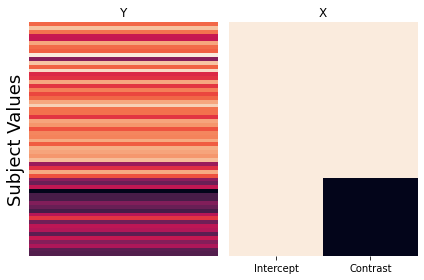
Another way to compare two different groups is by creating a model with an intercept and contrast between the two groups.
Let’s now run another simulation to see how these beta estimates differ from the dummy code model.
group1_params = {'n':20, 'mean':10, 'sd':2}
group2_params = {'n':20, 'mean':5, 'sd':2}
group1 = group1_params['mean'] + np.random.randn(group1_params['n']) * group1_params['sd']
group2 = group2_params['mean'] + np.random.randn(group2_params['n']) * group2_params['sd']
y = np.hstack([group1, group2])
x = pd.DataFrame({'Intercept':np.ones(len(y)), 'Contrast':np.hstack([np.ones(group1_params['n']), -1*np.ones(group2_params['n'])])})
run_regression_simulation(x, y)
betas: [7.60615263 3.16144295]
beta1 + beta2: 10.767595577579165
beta1 - beta2: 4.444709673800184
mean(group1): 10.767595577579163
mean(group2): 4.4447096738001814
mean(group1) - mean(group2): 6.322885903778982
mean(y): 7.606152625689674

So, just as before, the intercept reflects the mean of \(y\). Now can you figure out what \(\beta_1\) is calculating?
It is the average distance of each group to the mean. The mean of group 1 is \(\beta_0 + \beta_1\) and the mean of group 2 is \(\beta_0 - \beta_1\).
Remember that in our earlier discussion of contrast codes, we noted the importance of balanced codes across regressors. What if the group sizes are unbalanced? Will this effect our results?
To test this, we will double the sample size of group1 and rerun the simulation.
group1_params = {'n':40, 'mean':10, 'sd':2}
group2_params = {'n':20, 'mean':5, 'sd':2}
group1 = group1_params['mean'] + np.random.randn(group1_params['n']) * group1_params['sd']
group2 = group2_params['mean'] + np.random.randn(group2_params['n']) * group2_params['sd']
y = np.hstack([group1, group2])
x = pd.DataFrame({'Intercept':np.ones(len(y)), 'Contrast':np.hstack([np.ones(group1_params['n']), -1*np.ones(group2_params['n'])])})
run_regression_simulation(x, y)
betas: [7.98765299 2.16002722]
beta1 + beta2: 10.147680205027868
beta1 - beta2: 5.827625771635669
mean(group1): 10.147680205027864
mean(group2): 5.8276257716356685
mean(group1) - mean(group2): 4.320054433392196
mean(y): 8.707662060563798
Looks like the beta estimates are identical to the previous simulation. This demonstrates that we do not need to adjust the weights of the number of ones and zeros to sum to zero. This is because the beta is estimating the average distance from the mean, which is invariant to group sizes.
Independent-Samples T-Test - Group Intercepts#
The third way to calculate an independent samples t-test using a regression is to split the intercept into two separate binary regressors with each reflecting the membership of each group. There is no need to include an intercept as it is simply a linear combination of the other two regressors.
group1_params = {'n':20, 'mean':10, 'sd':2}
group2_params = {'n':20, 'mean':5, 'sd':2}
group1 = group1_params['mean'] + np.random.randn(group1_params['n']) * group1_params['sd']
group2 = group2_params['mean'] + np.random.randn(group2_params['n']) * group2_params['sd']
y = np.hstack([group1, group2])
x = pd.DataFrame({'Group1':np.hstack([np.ones(len(group1)), np.zeros(len(group2))]), 'Group2':np.hstack([np.zeros(len(group1)), np.ones(len(group2))])})
run_regression_simulation(x, y)
betas: [9.41009741 4.34939829]
beta1 + beta2: 13.759495698990353
beta1 - beta2: 5.060699128393246
mean(group1): 9.410097413691801
mean(group2): 4.3493982852985535
mean(group1) - mean(group2): 5.060699128393248
mean(y): 6.879747849495177
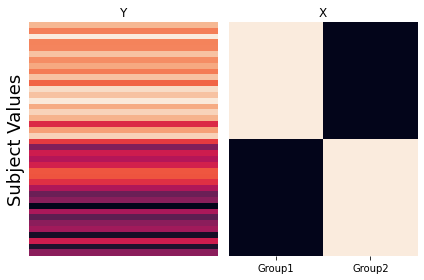
This model is obviously separately estimating the means of each group, but how do we know if the difference is significant? Any ideas?
Just like the single subject regression models, we would need to calculate a contrast, which would simply be \(c=[1 -1]\).
All three of these different approaches will yield identical results when performing a hypothesis test, but each is computing the t-test slightly differently.
Paired-Samples T-Test#
Now let’s demonstrate that a paired-samples t-test can also be computed using a regression. Here, we will need to create a long format dataset, in which each subject \(s_i\) has two data points (one for each condition \(a\) and \(b\)). One regressor will compute the contrast between condition \(a\) and condition \(b\). Just like before, we need to account for the mean, but instead of computing a grand mean for all of the data, we will separately model the mean of each participant by adding \(n\) more binary regressors where each subject is indicated in each regressor.
This simulation will be slightly more complicated as we will be adding subject level noise to each data point. In this simulation, we will assume that \(\epsilon_i = \mathcal{N}(30, 10)\)
a_params = {'mean':10, 'sd':2}
b_params = {'mean':5, 'sd':2}
sample_params = {'n':20, 'mean':30, 'sd':10}
y = []; x = []; sub_id = [];
for s in range(sample_params['n']):
sub_mean = sample_params['mean'] + np.random.randn()*sample_params['sd']
a = sub_mean + a_params['mean'] + np.random.randn() * a_params['sd']
b = sub_mean + b_params['mean'] + np.random.randn() * b_params['sd']
y.extend([a,b])
x.extend([1, -1])
sub_id.extend([s]*2)
y = np.array(y)
sub_means = pd.DataFrame([sub_id==x for x in np.unique(sub_id)]).T
sub_means = sub_means.replace({True:1,False:0})
X = pd.concat([pd.Series(x), sub_means], axis=1)
run_regression_simulation(X, y, paired=True)
betas: [38.56447613 35.08912938 42.0287038 22.7343386 28.18762639 42.88390721
7.0837409 43.58511337 22.66066626 42.75568132 37.21848932 19.9169548
36.84854258 30.06708857 44.8072347 34.76752398 34.36573871 42.14435925
22.91057627 52.88492285]
contrast beta: 2.545226964528254
mean(subject betas): 36.62046768344662
mean(y): 36.620467683446634
mean(a): 39.16569464797489
mean(b): 34.07524071891838
mean(a-b): 5.090453929056513
sum(a_i-mean(y_i))/n: 2.5452269645282555

Okay, now let’s try to make sense of all of these numbers. First, we now have \(n\) + 1 \(\beta\)’s. \(\beta_0\) corresponds to the between condition contrast. We will call this the contrast \(\beta\). The rest of the \(\beta\)’s model each subject’s mean. We can see that the means of all of these subject \(\beta\)’s corresponds to the overall mean of \(y\).
Now what is the meaning of the contrast \(\beta\)?
We can see that it is not the average within subject difference between the two conditions as might be expected given a normal paired-samples t-test.
Instead, just like the independent samples t-test described above, the contrast value reflects the average deviation of a condition from each subject’s individual mean.
where \(n\) is the number of subjects, \(a\) is the condition being compared to \(b\), and the \(mean(y_i)\) is the subject’s mean.
Linear and Quadratic contrasts#
Hopefully, now you are starting to see that all of the different statistical tests you learned in intro stats (e.g., one-sample t-tests, two-sample t-tests, ANOVAs, and regressions) are really just a special case of the general linear model.
Contrasts allow us to flexibly test many different types of hypotheses within the regression framework. This allows us to test more complicated and precise hypotheses than might be possible than simply turning everything into a binary yes/no question (i.e., one sample t-test), or is condition \(a\) greater than condition \(b\) (i.e., two sample t-test). We’ve already explored how contrasts can be used to create independent and paired-samples t-tests in the above simulations. Here we will now provide examples of how to test more sophisticated hypotheses.
Suppose we manipulated the intensity of some type of experimental manipulation across many levels. For example, we increase the working memory load across 4 different levels. We might be interested in identifying regions that monotonically increase as a function of this manipulation. This would be virtually impossible to test using a paired contrast approach (e.g., t-tests, ANOVAs). Instead, we can simply specify a linear contrast by setting the contrast vector to linearly increase. This is as simple as [0, 1, 2, 3]. However, remember that contrasts need to sum to zero (except for the one-sample t-test case). So to make our contrast we can simply subtract the mean - np.array([0, 1, 2, 3]) - np.mean((np.array([0, 1, 2, 3)), which becomes \(c_{linear} = [-1.5, -0.5, 0.5, 1.5]\).
Regions involved in working memory load might not have a linear increase, but instead might show an inverted u-shaped response, such that the region is not activated at small or high loads, but only at medium loads. To test this hypothesis, we would need to construct a quadratic contrast \(c_{quadratic}=[-1, 1, 1, -1]\).
Let’s explore this idea with a simple simulation.
# First let's make up some hypothetical data based on different types of response we might expect to see.
sim1 = np.array([.3, .4, .7, 1.5])
sim2 = np.array([.4, 1.5, .8, .4])
x = [1,2,3,4]
# Now let's plot our simulated data
f,a = plt.subplots(ncols=2, sharey=True, figsize=(10, 5))
a[0].bar(x, sim1)
a[1].bar(x, sim2)
a[0].set_ylabel('Simulated Voxel Response', fontsize=18)
a[0].set_xlabel('Working Memory Load', fontsize=18)
a[1].set_xlabel('Working Memory Load', fontsize=18)
a[0].set_title('Monotonic Increase to WM Load', fontsize=18)
a[1].set_title('Inverted U-Response to WM Load', fontsize=18)
Text(0.5, 1.0, 'Inverted U-Response to WM Load')
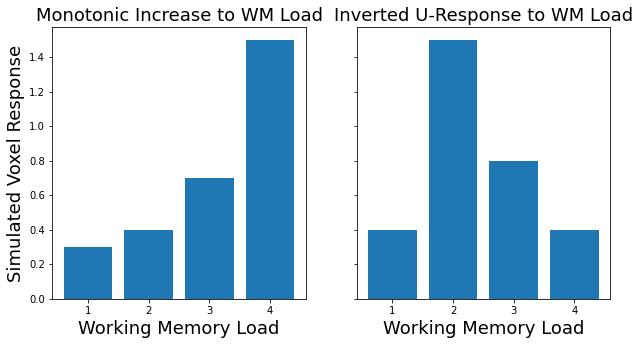
See how the data appear to have a linear and quadratic response to working memory load?
Now let’s create some contrasts and see how a linear or quadratic contrast might be able to detect these different predicted responses.
# First let's create some contrast codes.
linear_contrast = np.array([-1.5, -.5, .5, 1.5])
quadratic_contrast = np.array([-1, 1, 1, -1])
print(f'Linear Contrast: {linear_contrast}')
print(f'Quadratic Contrast: {quadratic_contrast}')
# Now let's test our contrasts on each dataset.
sim1_linear = np.dot(sim1, linear_contrast)
sim1_quad = np.dot(sim1, quadratic_contrast)
sim2_linear = np.dot(sim2, linear_contrast)
sim2_quad = np.dot(sim2, quadratic_contrast)
# Now plot the contrast results
f,a = plt.subplots(ncols=2, sharey=True, figsize=(10,5))
a[0].bar(['Linear','Quadratic'], [sim1_linear, sim1_quad])
a[1].bar(['Linear','Quadratic'], [sim2_linear, sim2_quad])
a[0].set_ylabel('Contrast Value', fontsize=18)
a[0].set_xlabel('Contrast', fontsize=18)
a[1].set_xlabel('Contrast', fontsize=18)
a[0].set_title('Monotonic Increase to WM Load', fontsize=18)
a[1].set_title('Inverted U-Response to WM Load', fontsize=18)
Linear Contrast: [-1.5 -0.5 0.5 1.5]
Quadratic Contrast: [-1 1 1 -1]
Text(0.5, 1.0, 'Inverted U-Response to WM Load')
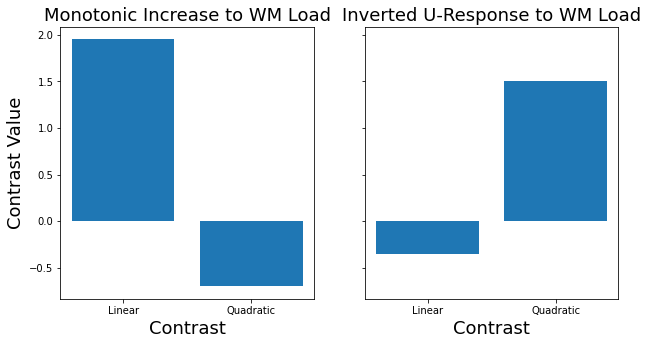
As you can see, the linear contrast is sensitive to detecting responses that monotonically increase, while the quadratic contrast is more sensitive to responses that show an inverted u-response. Both of these are also signed, so they could also detect responses in the opposite direction.
If we were to apply this to real brain data, we could now find regions that show a linear or quadratic responses to an experimental manipulation across the whole brain. We would then test the null hypothesis that there is no group effect of a linear or quadratic contrast at the second level.
Hopefully, this is starting you a sense of the power of contrasts to flexibly test any hypothesis that you can imagine.
Exercises#
1. Which regions are more involved with visual compared to auditory sensory processing?#
Create a contrast to test this hypothesis
run a group level t-test
plot the results
write the file to your output folder.
2. Which regions are more involved in processing numbers compared to words?#
Create a contrast to test this hypothesis
run a group level t-test
plot the results
write the file to your output folder.
3. Are there gender differences?#
In this exercise, create a two sample design matrix comparing men and women on arithmetic vs reading.
You will first have to figure out the subjects gender using the using the participants.tsv file.
Create a contrast to test this hypothesis
run a group level t-test
plot the results
write the file to your output folder.